




Vhost-User Feature for QEMU
Vhost-User Applied to Snabbswitch Ethernet Switch
The purpose of this document is to introduce the reader to the vhost-user feature for QEMU that was developed by Virtual Open Systems for use by the Snabbswitch Ethernet switch. The architecture of vhost-user and Vapp are covered in this document. The reader will also be walked through building QEMU with the vhost-user feature, and testing it with the Vapp reference implementation.
The Case for Vhost-User
One way virtual machines under QEMU/KVM, may get access to an external network is via the virtio_net paravirtualized network driver. In the Virtio infrastructure, a virtio_pci driver implements a 'virtio ring' which implements a standard mechanism to implement paravirtualized drivers. This means that a virtual PCI device emulated by QEMU, serves as the transport mechanism that implements the Virtio ring on x86 Virtual Machines. On top of this machine specific infrastructure, generic Virtio drivers will use a generic API to set up virtqueues, that will be 'kicked' whenever buffers with new data are placed in them.
Virtio_net, is a network driver implementation based on Virtio; a guest running the virtio_net network driver, will share a number of virtqueues with the QEMU process that hosts that guest. In this fashion, the QEMU process will receive the network traffic from the guest, and forward it to the host network. However, this implies that all guest traffic has to be handled by the QEMU process before it can be processed further by the host's network stack.
A solution to this problem is vhost, which allows a userspace process to share a number of virtqueues directly with a kernel driver. The transport mechanism in this case is the ability of the kernel side to access the userspace application memory, and a number of ioeventfds and irqfds to serve as the kick mechanism. A QEMU guest will still use an emulated PCI device, as the control plane is still handled by QEMU; however once a virtqueue has been set up, it will use the vhost API to pass direct control of a virtqueue to a kernel driver. In this model, a vhost_net driver will directly pass guest network traffic to a TUN device directly from the kernel side, improving performance significantly.
However, this is still not the ideal solution for Snabbswitch, a software Ethernet switch running completely in userspace. Snabbswitch, driving Ethernet hardware directly, can demonstrate high network performance running almost completely in userspace. For Snabbswitch to reach the same level of performance with Virtual Machines as it is currently achieving with physical Ethernet hardware, it will need to directly interface with a QEMU/KVM Virtual Machine through Virtio, while minimizing processing by intermediate software, which also includes the kernel.
As with QEMU/KVM Virtual Machine to host networking, where the QEMU process is an intermediate that needs to be skipped in order to enjoy improved performance, likewise with the Snabbswitch application, which is running in userspace, the Linux kernel is an overhead that can be skipped. To solve this problem we introduce the vhost-user infrastructure.
Vhost-user Overview
The goal of vhost-user is to implement such a Virtio transport, staying as close as possible to the vhost paradigm of using shared memory, ioeventfds and irqfds. A UNIX domain socket based mechanism allows to set up the resources used by a number of Vrings shared between two userspace processes, which will be placed in shared memory. The mechanism also configures the necessary eventfds to signal when a Vring gets a kick event from either side.
Vhost-user has been implemented in QEMU via a set of patches, giving the option to pass any virtio_net Vrings directly to another userspace process, implementing a virtio_net backend outside QEMU. This way, direct Snabbswitch to a QEMU guest virtio_net communication can be realized.
QEMU already implements the vhost interface for a fast zero-copy guest to host kernel data path. Configuration of this interface relies on a series of ioctls that define the control plane. In this scenario, the QEMU network backend invoked is the “tap” netdev. A usual way to run it is:
$ qemu -netdev type=tap,script=/etc/kvm/kvm-ifup,id=net0,vhost=on \
-device virtio-net-pci,netdev=net0
The purpose of the vhost-user patches for QEMU is to provide the infrastructure and implementation of a user space vhost interface. The fundamental additions of this implementation are:
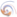 Added an option to -mem-path to allocate guest RAM as memory that can be shared with another process.
Added an option to -mem-path to allocate guest RAM as memory that can be shared with another process.
Use a Unix domain socket to communicate between QEMU and the user space vhost implementation.
The user space application will receive file descriptors for the pre-allocated shared guest RAM. It will directly access the related vrings in the guest's memory space.
Overall architecture of vhost-user
In the target implementation the vhost client is in QEMU. The target backend is Snabbswitch.
Compilation and Usage
QEMU Compilation
A version of QEMU patched with the latest vhost-user patches can be retrieved from the Virtual Open Systems repository at https://github.com/virtualopensystems/qemu.git, branch vhost-user-v5.
To clone it:
$ git clone -b vhost-user-v5 https://github.com/virtualopensystems/qemu.git
Compilation is straightforward:
$ mkdir qemu/obj
$ cd qemu/obj/
$ ../configure --target-list=x86_64-softmmu
$ make -j
This will build QEMU as qemu/obj/x86_64-softmmu/qemu-system-x86_64.
Using QEMU with Vhost-user
To run QEMU with the vhost-user backend, one has to provide the named UNIX domain socked that needs to be already opened by the backend:
$ qemu -m 1024 -mem-path /hugetlbfs,prealloc=on,share=on \
-netdev type=vhost-user,id=net0,file=/path/to/socket \
-device virtio-net-pci,netdev=net0
Vapp Reference Implementation
The reference implementation of the vhost client/backend concept is called vapp. This can serve as a test case for the vhost-user protocol and as a way to boostrap implementation of a new client or server.
The source for Vapp is in the Virtual Open Systems public github repository:
$ git clone https://github.com/virtualopensystems/vapp.git
Compilation is straightforward:
$ cd vapp
$ make
To run the vhost-user reference backend:
$ ./vhost -s ./vhost.sock
The reference client can be run like this:
$ ./vhost -q ./vhost.sock
Snabbswitch with Vhost-user Support
The vhost-user support for Snabbswitch is being maintained by SnabbCo. The code can be obtained from the vhostuser branch of the official Snabbswitch repository:
$ git clone -b vhostuser --recursive https://github.com/SnabbCo/snabbswitch.git
$ cd snabbswitch
$ make
It can be tested as such:
$ sudo src/snabbswitch -t apps.vhost.vhost_user
Design and Architecture
Generic Userspace to Userspace Virtio Architecture
The currently Virtio transports take into account only the case of a guest operating system driver communicating with a Virtio backend running in the Hypervisor; in fact, in the case of QEMU with KVM only two cases are taken into account:
Guest Virtio driver to a Virtio backend running inside QEMU. This is the most common case. On x86 the virtio_pci transport is used to exchange Vrings (Virtio's basic data set) and exchange notifications of new data (kicks). Actual data will be accessed directly by QEMU, since it has access to the guest's memory space.
Guest Virtio driver to a Vhost backend running as part of the Linux kernel. This is an optimization which allows the host kernel to directly handle guest traffic without involving an exit to userspace (QEMU). In this case virtio_pci is still used for configuration, however QEMU will setup eventfds for the kicks coming from the guest and setup a Vhost driver to directly respond to them.
It is apparent that we require a third option, which is Guest Virtio driver to a Virtio backend running in a userspace process. Existing infrastructure in KVM allows us to match Virtio events (kicks) to eventfds, however we need a standard interface to pass control of them to a host userspace process. We also need to enable that process to access any memory where the guest may place any buffers or data structures it will exchange with the host.
The interface is based on shared memory, and passing of eventfds, similar to the already proven interface implemented by vhost.
The Vapp Reference Implementation
Since this essentially a new Virtio mechanism, however similar to the existing Vhost architecture, a test case is developed to prove the concept and the code behind putting the Virtio backend in an userspace application.
We call this implementation Vapp, and there are essentially two major components; the Vapp Client plays the role of the virtual machine, and the Vapp Server plays the role of the Virtio backend. In the implemented test case, the application running on the client side creates a data packet and places it in the Vapp client's implementation of Vring. The Vapp Client and the Vapp Server will share a range of memory where the Vrings and the data buffers will be placed, and will communicate using eventfds. The setup mechanism for this is based on a simple Unix domain socket and uses an interface that has similar capabilities to the Vhost kernel implementation.
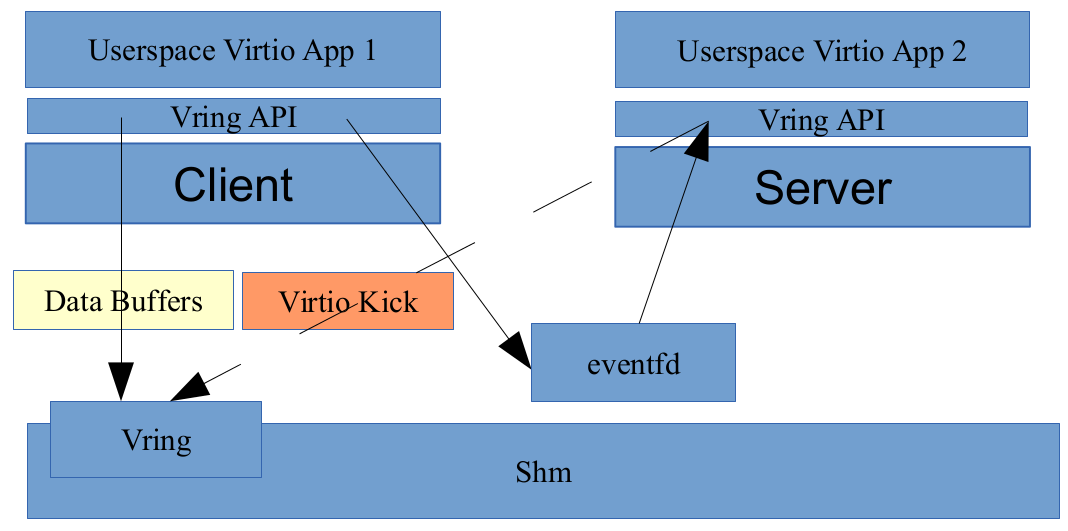
Vapp Client Server Architecture
Server Vring implementation
This Vring architecture is generic enough that it can be also implemented in QEMU (for the client side) and Snabbswitch (for the server side). However in the real world model which will be discussed in the next sections, the Vring implementation will not be running inside QEMU but inside the guest operating system. QEMU will merely setup the connection between the guest Virtio transport (virtio_pci), and the target host userspace process.
The implications of this is that the Vring implementation in the server must precisely follow the Virtio specifications to the letter. Additionally, the virtio_pci driver can be interfaced with by using eventfds set up via KVM (ioeventfd and irqfd) and by accessing the guest's address space to reach to the shared buffers that include the actual data produced (or consumed) by the Virtio driver.
For the Vapp Server to successfully communicate and exchange data via Vrings with a virtio_pci driver in the guest, it will need to set up at least the following:
Access to the guest's address space, where the buffers with data reside.
Handlers to eventfds that respond to (or produce) Virtio events.
Shared access to Virtio data structures, including most importantly the Vrings.
This model has already been demonstrated successfully with Vhost, where a Vring implementation running in the host's kernel space can successfully directly interface with a Vring implementation running via virtio_pci in the guest. The main differences compared to the Vhost kernel implementation are:
We are running the Virtio backend in userspace. Instead of a ioctl interface, we implement a Unix domain socket and shared memory based interface to implement this.
We do not need to set a TAP device. Our implementation is agnostic to what the target application running the backend will do with the traffic it will receive.
Setup Mechanism
For the described Virtio mechanism to work, we need a setup interface to initialize the shared memory regions and exchange the event file descriptors. A Unix domain socket implements an API which allows us to do that. This straightforward socket interface can be used to initialize the userspace Virtio transport (vhost-user), in particular:
Vrings are determined at initialization and are placed in shared memory between the two processed.
For Virtio events (Vring kicks) we shall use eventfds that map to Vring events. This allows us compatibility with the QEMU/KVM implementation described in the next chapter, since KVM allows us to match events coming from virtio_pci in the guest with eventfds (ioeventfd and irqfd).
Sharing file descriptors between two processes differs than sharing them between a process and the kernel. One needs to use sendmsg over a Unix domain socket with SCM_RIGHTS set.
Login or register to access full information
